Introduction
Are you frustrated with endless jargon and complex steps when trying to integrate Scikit into your workflow? You're not alone. For many, incorporating Scikit Learn into their workflow can be a challenging task.
But understanding its potential and leveraging it doesn't have to be an uphill battle.
That's why we're here with a simple guide that walks you through five easy-to-follow steps to integrate Scikit Learn into your workflow.
We'll start from the basics, like preparing your data for machine learning and choosing the right algorithm, to more advanced processes, such as model training and fine-tuning.
By the end of this blog, you'll find that integrating Scikit Learn isn't so intimidating after all. Streamline your workflow, make the most of Scikit Learn's capabilities, and tackle those machine-learning projects with newfound confidence.
Step one, coming right up!
Introduction to Scikit Learn
Scikit Learn, often known as scikit-learn in the programming sphere, is an open-source machine learning library for Python.
Designed with simplicity and efficiency, it offers a variety of tools to analyse and model data, whether you're a novice or a skilled data analyst.
From regression, classification, clustering to dimension reduction and model selection, Scikit Learn leaves no stone unturned.
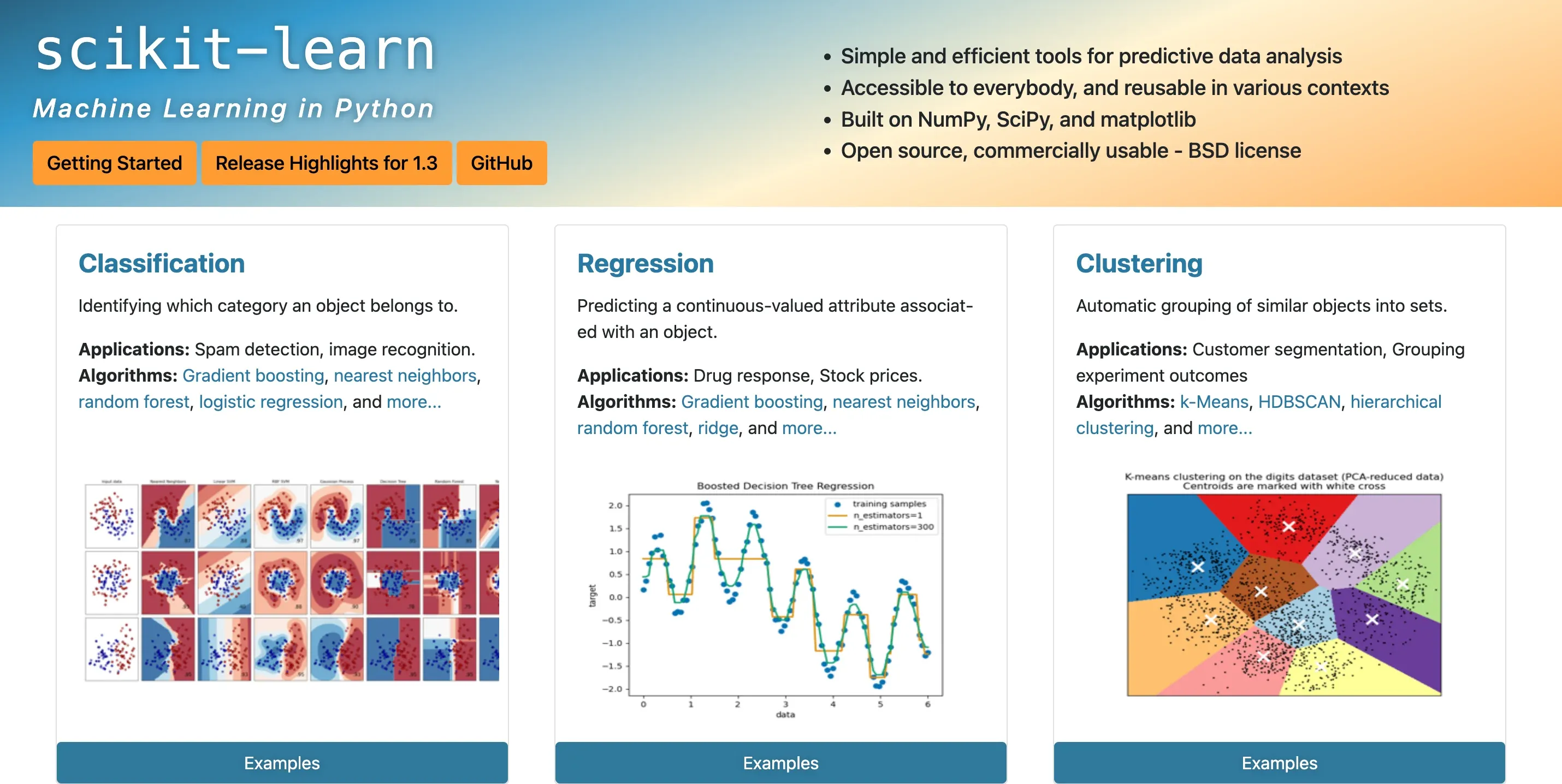
Why is Scikit Learn so useful for ML?
Highlighting its importance, Scikit Learn is the go-to library for many, and why not? Given the fact that it's built on NumPy, SciPy, and matplotlib, it offers a convenient and extensive array of machine learning algorithms.
A key player in the landscape of machine learning, Scikit Learn's impact is far-reaching and undeniable.
Setting up Scikit Learn
Setting up Scikit Learn is as simple as it gets. The primary requirement is Python, as Scikit Learn is a Python library.
To install scikit learn, all you need to do is run the following command: “pip install -U scikit-learn”
Understanding basic terminology in Scikit learn
Before delving into Scikit Learn, basic terminologies like 'features', 'labels' or 'targets', 'training set', and 'test set' must be embraced.
Giving you a head start, a feature is an input variable - the column of the dataset, and labels or targets are the output variable, which the model predicts.
Quick tour of Scikit learn documentation
The documentation of Scikit Learn is an extensive hub of knowledge, quite a resource for both beginners and experts.
Right from installation guides to tutorials and module references, it offers a comprehensive database to dive into Scikit Learn's functionalities.
Step 1
Load your data
It's about time to load your data and here's how.
We'll explore importing libraries and datasets, cleaning data, processing categorical variables, and finally, splitting the data into training and test sets with Scikit Learn.
Importing necessary libraries and datasets
Before performing any operation, the necessary libraries and datasets must be imported.
To draw the power of Scikit Learn, use import sklearn.
Understanding your dataset
To successfully analyse with Scikit Learn, understanding your dataset fully is paramount.
It's crucial to identify the type of variables and understand the structure of your data.
Data cleaning with Scikit Learn
A clean dataset is a prerequisite for accurate analysis.
Duplicates and irrelevant variables should be removed, and formats should be standardized, all of which can be done with Scikit Learn.
This example removes null values with the mean of each feature:
from sklearn.impute import SimpleImputerimp = SimpleImputer(strategy="mean")X_clean = imp.fit_transform(X)
Dealing with categorical variables using Scikit Learn
Scikit Learn simplifies handling categorical variables, such as those with string values.
Tools like OneHotEncoder or LabelEncoder convert categorical data into a format that can be used in machine learning algorithms.
Here's how you can use OneHotEncoder to handle categorical variables:
from sklearn.preprocessing import OneHotEncoderenc = OneHotEncoder(handle_unknown='ignore')X_enc = enc.fit_transform(X)
Splitting the data into train and test sets with Scikit Learn
Training models on the entire dataset could lead to overfitting, which is why data is split into training and test sets. Scikit Learn provides the function ‘train_test_split’ to achieve this.
Step 2
Preprocess your data
Preprocessing data can make a world of difference to your analysis.
Learn about feature scaling, handling missing values, the aftermath of preprocessing on the dataset, and potential traps to avoid.
Overview of preprocessing
Preprocessing is about making raw data comprehensive.
Scikit Learn simplifies preprocessing through tools to standardize or normalize data, handle missing values, and more.
Feature scaling with Scikit Learn
Feature scaling ensures all features contribute fairly to the final result.
Scikit Learn standardization or normalization functions level the playing field for all features.
Use this:
from sklearn.preprocessing import StandardScalersc = StandardScaler()X_train = sc.fit_transform(X_train)X_test = sc.transform(X_test)
Handling missing values with Scikit Learn
Handling missing values with Scikit Learn
This function replaces missing values with the mean value of each feature:
from sklearn.impute import SimpleImputerimp = SimpleImputer(missing_values=np.nan, strategy='mean')X_imp = imp.fit_transform(X)
Remember that while applying these examples to your own projects, you may need to modify the code to match your specific needs.
Effect of preprocessing on the dataset
Preprocessing generally modifies the dataset. While the impact may vary depending on the nature of your data and the preprocessing techniques used, the result is a polished and ready-to-use dataset.
Common errors to avoid in preprocessing
Watch out for common pitfalls during preprocessing. Avoid ignoring outliers, missing values, leaking information from test sets, or relying on inappropriate preprocessing strategies.
Use Scikit Learn wisely for data analysis that delivers!
Step 3: Choosing the Right Model
Choosing the right model lays a crucial foundation for effective machine learning processes. The model you select determines the accuracy and efficiency of your data science project.
In essence, without a suitable model, even rich and well-refined datasets would fail to deliver valuable insights or predictions.
from sklearn import linear_modelreg = linear_model.LinearRegression()
Overview of Scikit Learn Algorithms
Scikit Learn is blessed with a myriad of ingenious algorithms, each tailored for different needs and problem statements.
From Supervised Learning (like linear regression, SVM, and k-nearest neighbors) to Unsupervised Learning (like Principal Component Analysis, Matrix Factorization, and Clustering) and Ensemble Methods, this toolbox has it all.
Tips to Choose the Right Model
With numerous models to choose from, how do you know which one is "The One"? Well, there is no one-size-fits-all.
Understanding your problem statement and dataset thoroughly, matching the type of problem (classification, regression, clustering, etc.) to the fitting model family, and comparing the performance using cross-validation are highly recommended.
Using a decision tree for classificationfrom sklearn import treeclf = tree.DecisionTreeClassifier()
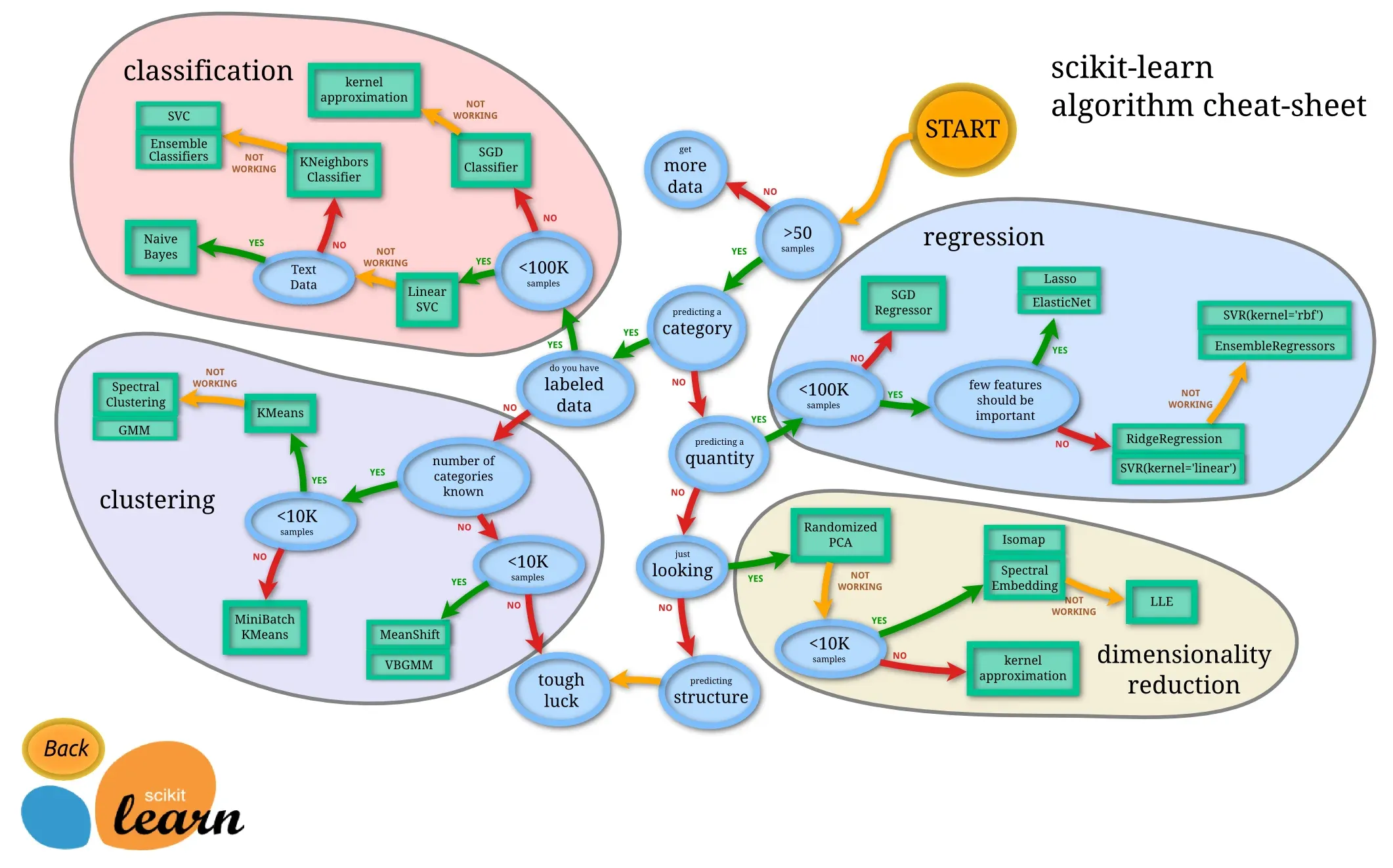
Scikit Learn Cheat Sheet for Model Selection
Thankfully, Scikit Learn comes to the rescue with its intuitive cheat sheet that simplifies model selection.
It leverages a flowchart model to direct users towards an appropriate model based on the nature and complexity of their problem.
Practical Example of Choosing an Algorithm in Scikit Learn
In a binary classification problem, for instance, a suitable starting point could be a Logistic Regression model, and here's how you can implement it:
from sklearn.linear_model import LogisticRegressionlr = LogisticRegression()
Step 4: Train Your Model
Training your model is akin to teaching a baby new words, where your dataset is the vocabulary book.
In essence, it's all about using the 'training' data to influence and shape the model's understanding and predictions.
Training a logistic regression modellr.fit(X_train, y_train)
How to Train a Model in Scikit Learn
Training a model in Scikit Learn is a breeze. After selecting the right model, you use the 'fit()' function to initiate the training process on your data.
Understanding Model Parameters
A model's parameters are its life force. Like an artist working with various brush sizes and shades, fine-tuning these parameters paints a clearer and more accurate picture of your data.
Monitoring Model Training
Keeping an eye on your model as it learns is essential to detect anomalies early.
Be on the watch for signs of underfitting or overfitting and make adjustments as necessary.
Interpreting Model Outputs
Post training period, the model churns out predictions based on its learning.
Interpreting these outputs, in line with your problem statement, leads to concrete insights and action items.
Making predictionslr.predict(X_test)
Step 5: Evaluate and Refine Your Model
Once your model is trained, it needs to be tested on unseen data.
This evaluation phase determines how well the model generalizes outside of its training set, ensuring its robustness and reliability.
The score function returns the accuracy of the modelscore = lr.score(X_test, y_test)
Common Evaluation Metrics in Scikit Learn
The evaluation metric used depends on our model. For example, Mean Squared Error (MSE) is commonly used for regression problems while accuracy, precision, and recall are employed for classification problems.
from sklearn.metrics import mean_squared_errormse = mean_squared_error(y_test, y_pred)
Cross-validation in Scikit Learn
Cross-validation is an effective method for assessing the performance and stability of your model.
It involves dividing your data into 'k' groups or folds, using one for testing and the remainder for training.
from sklearn.model_selection import cross_val_scorescores = cross_val_score(lr, X, y, cv=5)
Suggested Reading: How to get started with Scikit Learn: A step-by-step tutorial
Hyperparameter Tuning with Scikit Learn
Hyperparameters, unlike parameters, are not learned from the data but are set prior to the training phase.
Tuning hyperparameters can significantly improve the performance of the model.
from sklearn.model_selection import GridSearchCVparameters = {'C': [0.1, 1, 10, 100, 1000]}clf = GridSearchCV(lr, parameters)
Re-training Your Refined Model
Lastly, following evaluation and refinement, models are re-trained on the entire dataset, incorporating all the valuable data and the new insights gained, ready to make predictions on fresh data.
Re-training the modellr.fit(X, y)
With these steps in place, tackling your data science projects with the Scikit-Learn library would be an enjoyable and informative journey.
Deploying Your Model
Model deployment is the process of integrating the machine learning model into a production environment, allowing it to make predictions on new data.
A successfully deployed model can provide valuable insights, helping drive decision-making and automating various tasks.
Steps to Deploy a Scikit Learn Model
- Save your model: Use Scikit Learn's joblib or Python's pickle to serialize your trained model, saving it as a file.
from joblib import dumpdump(model, 'model_name.joblib') - Load the saved model: Use joblib or pickle to deserialize the saved file in the production environment.
from joblib import loadmodel = load('model_name.joblib') - Create a REST API (optional): To call your model from various applications, expose it using a REST API. You could use Flask, Django, or other web frameworks for this purpose.
- Deploy the model on a platform: Select the suitable platform for deployment, such as Heroku, Microsoft Azure, Google Cloud, or Amazon Web Services.
- Test the deployed model: Evaluate the model's performance in the production environment by testing its predictions on new data.
Saving and Loading a Model with Scikit Learn
To save and load a trained Scikit Learn model, use the joblib module. Here's a simple example:
# Saving the modelfrom joblib import dumpdump(lr, 'logistic_regression_model.joblib')# Loading the saved modelfrom joblib import loadloaded_model = load('logistic_regression_model.joblib')
Example of a Deployed Scikit Learn Model
Imagine you have created a sentiment analysis model using Scikit Learn and you want to deploy it to analyze customer reviews on your website:
- Save the trained model as a .joblib file.
- Load the model in your server-side code (e.g., using Flask or Django).
- Create an API endpoint that takes customer reviews as input, processes them using the model, and returns sentiment predictions.
- Integrate this API endpoint with your website, displaying the predicted sentiment alongside each customer review.
Common Post-Deployment Issues
- Incompatible software versions: Ensure the production environment software versions are consistent with the development environment.
- Inconsistent data preprocessing: Standardize data preprocessing across development and production environments to prevent inaccurate predictions.
- Scalability and performance: Monitor your model's performance in real-time and make necessary adjustments, e.g., using load balancing, to maintain responsiveness.
Scikit Learn Best Practices
- Keep data preprocessing consistent.
- Perform thorough model evaluation and tuning before deployment.
- Optimize your model for performance and efficiency.
- Monitor the model in the production environment and update as needed.
- Collaborate with the Scikit Learn community for insights and expert advice.
Importance of Following Best Practices
Adhering to best practices ensures smooth deployment, optimal performance, model stability, and accurate predictions, all of which are crucial factors in realizing the full potential of Scikit Learn.
Effective Data Handling in Scikit Learn
- Consistent data preprocessing steps across development and production environments.
- Use built-in Scikit Learn functions, like train_test_split and Pipeline, for seamless data handling.
- Always validate and clean your input data before processing.
Ensuring Model Reproducibility
- Make sure all random number generation is controlled by a fixed seed.
- Document all versions of software, dependencies, and data.
- Share your code, data, and steps taken in preprocessing through version control systems.
Pointers for Efficient Computation
- Select the appropriate algorithm for your data size and complexity.
- Use parallel processing or GPU computation capabilities when available.
- Continuously monitor and profile your code to identify bottlenecks and optimize them.
Leveraging the Scikit Learn Community
The Scikit Learn community offers valuable resources, insights, and forums to exchange knowledge and solve issues.
Engage with this community to get the most out of Scikit Learn.
Final Thoughts
Recap of Steps to Integrate Scikit Learn into Your Workflow:
- Install Scikit Learn
- Familiarize yourself with its capabilities
- Choose the right model
- Train the model
- Evaluate and refine the model
- Deploy the model
Mastering Scikit Learn empowers you to streamline data analysis and machine learning projects, making it an essential tool to excel in data science and unlock valuable insights from your data.
Keep practicing, experimenting, and learning with Scikit Learn to continually improve your data science skills and make the most of this versatile library.
Relevant Resources and Guides for Further Learning
- Scikit Learn Documentation: https://scikit-learn.org/stable/index.html
- Online tutorials, such as YouTube channels, blog articles, and online courses
- Books and academic papers on Scikit Learn and its applications
- Engage in the Scikit Learn community through GitHub, mailing lists, and user forums
Frequently Asked Questions (FAQs)
Why to integrate Scikit-learn into my workflow?
Scikit-learn can help you simplify data analysis tasks. Its user-friendly interface, wide array of algorithms, and powerful tools make it integral to efficient data science workflows.
How to start with Scikit-learn integration?
Start by installing Scikit-learn using pip or conda. Next, familiarize yourself with the library structure, loading datasets, and basic commands. It's best to follow along with a tutorial.
What's the most straightforward way to preprocess data with Scikit-learn?
Scikit-learn provides easy-to-use preprocessing functions. These include LabelEncoder for categorical data, StandardScaler for standardization, and a plethora of more specialized tools.
Can Scikit-learn help to choose the right ML algorithm?
Yes, Scikit-learn's abundance of algorithms is sortable by type (classification, regression, etc.)
Use their machine learning map to choose the right algorithm for your dataset and needs.
How to evaluate and improve my Scikit-learn models?
Scikit-learn offers evaluation metrics for classification (like accuracy, precision, recall) and regression (like R^2, MSE, MAE).
Use these metrics to understand and improve your model's performance.
