Looking for ways to make your data analysis work more streamlined and efficient? The answer might just be simpler than you think.
In a data-driven world, the ability to extract meaningful insights from vast amounts of data is a skill that's in high demand.
More often than not, the process can seem challenging and intricate. But that's where Scikit-Learn comes into play. It's simple, efficient, and handy, making it a preferred choice for data analysts globally.
With this blog, we'll delve into understanding Scikit-Learn, highlighting the features that can simplify and elevate your data analysis.
This blog is intended for anyone interested in data science, aspiring or experienced. We aim to make the ins and outs of Scikit-Learn approachable and easy to understand.
Let's get started!
What is Scikit-Learn?
Scikit-Learn is an open-source Python library that provides simple and efficient tools for data analysis, machine learning, and data mining tasks.
It has a wide range of algorithms, extensive documentation, and a highly active community contributing to its continuous development.
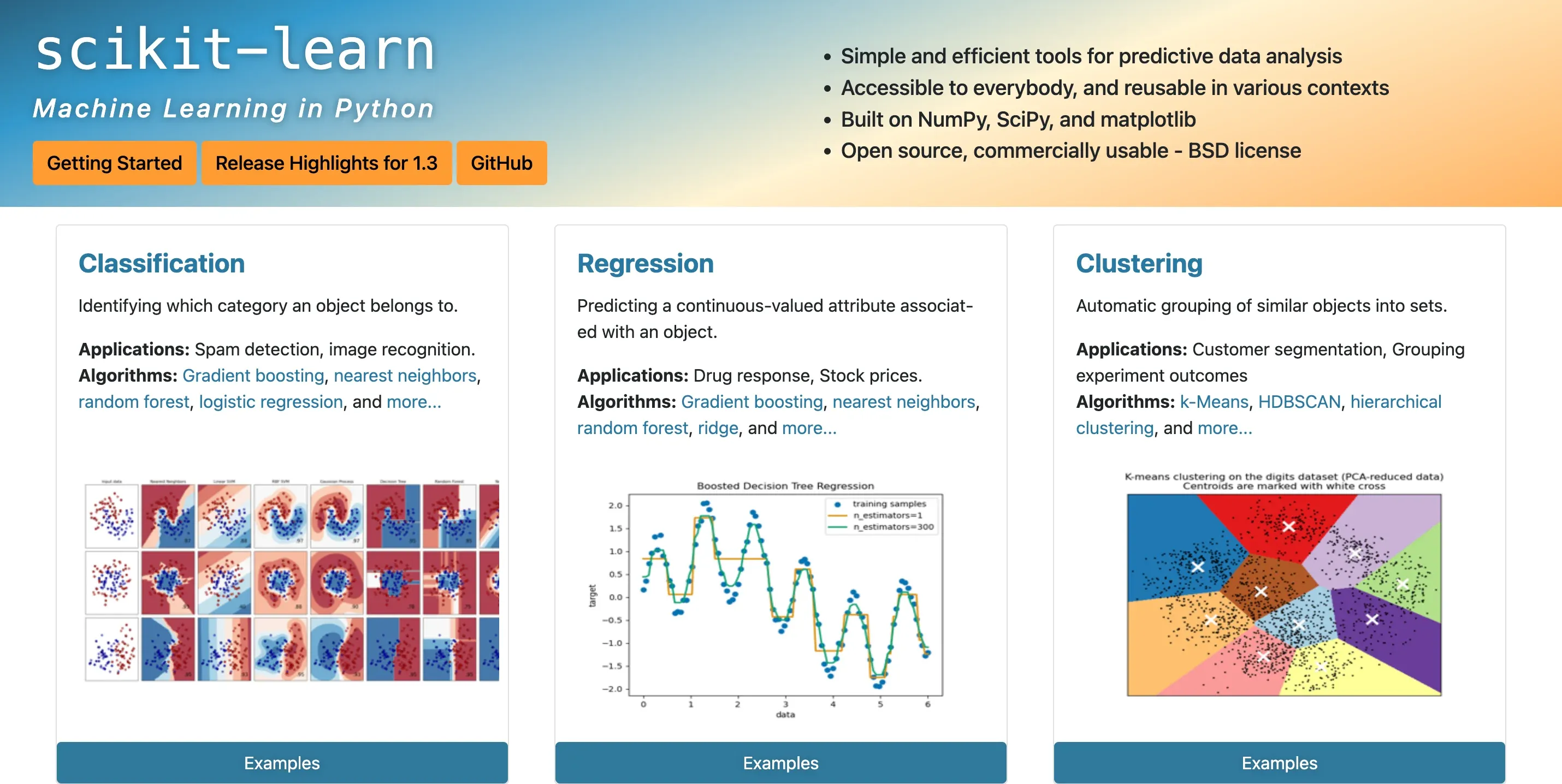
The Evolution of Scikit-Learn
Scikit-Learn was born out of a Google Summer of Code project in 2007 and has since grown into a mature, well-maintained library that is widely adopted in both academia and industry.
The needs of users and the community drives its development.
Scikit-Learn's Core Principles
The library is built on the core principles of simplicity, reusability, and efficiency.
It aims to provide a consistent API across different algorithms, enabling users to quickly switch between various methods and techniques without much hassle.
Using Scikit-Learn: A Quick Example
A typical workflow in Scikit-Learn involves loading data, preprocessing, applying algorithms, and evaluating the results.
With just a few lines of code, you can effortlessly perform complex tasks such as classification, regression, and clustering.
Scikit-Learn's Impact on Data Science
Scikit-Learn has greatly contributed to the growth of data science and machine learning, making it accessible and affordable for researchers, developers, and business professionals alike.
Its ease of use and extensive features make it an indispensable tool in data analysis.
Importance of Data Analysis
In this section, we will discuss the critical role of data analysis in various fields and why it has become a crucial skill for professionals today.
Gaining Valuable Insights from Data
Data analysis helps us extract valuable information from raw data, allowing us to make informed decisions and solve complex problems.
It enables businesses to identify trends, patterns, and relationships within their data, which can lead to better decision-making and improved performance.
Data-Driven Decision Making
Organizations can leverage data analysis to make data-driven decisions, reducing guesswork and mitigating risks.
This results in more efficient processes, better performance, and increased revenue.
Improving Customer Experience
By analyzing customer data, businesses can gain insights into their preferences, needs, and behavior patterns.
This knowledge enables the creation of personalized experiences, leading to increased customer satisfaction and loyalty.
Streamlining Operations
Data analysis can help organizations uncover inefficiencies, waste, and bottlenecks in their operations.
These insights enable process improvements and cost reductions, boosting overall performance and profitability.
Advancing Scientific Research
Data analysis plays a critical role in scientific research, helping researchers analyze and interpret experimental results.
It also aids in hypothesis testing, model development, and the discovery of new insights and knowledge.
Why choose Scikit Learn for Data Analysis?
Scikit-Learn is a powerful and versatile tool for data analysis tasks.
In this section, we will explore the reasons behind its popularity and why you should consider using it for your data analysis needs.
Ease of Use and Approachability
Scikit-Learn is designed to be simple and intuitive, making it accessible to users of varying skill levels.
Its consistent API, clear documentation, and numerous tutorials make it easy for beginners to get started with data analysis.
Variety of Algorithms
Scikit-Learn offers a comprehensive suite of algorithms for data analysis tasks, including classification, clustering, regression, and dimensionality reduction.
This broad range of options allows users to apply the most suitable technique for their specific use case.
Interoperability and Flexibility
Scikit-Learn smoothly integrates with popular Python libraries like NumPy, pandas, and matplotlib, making it versatile and easy to incorporate into your existing workflow.
Its consistent API also promotes the rapid development and testing of different algorithms.
Active Community Support
Scikit-Learn boasts a vibrant and supportive community, contributing to its continuous growth and improvement. Users benefit from many resources, including online forums, blogs, and workshops, which help them get the most out of the library.
Performance and Scalability
Scikit-Learn is designed to be efficient and performant, utilizing the power of the NumPy library for fast numerical computations.
Additionally, it supports parallel computing for certain tasks, increasing the speed and scalability of data analysis operations.
How Can Scikit Learn Enhance Your Data Analysis?
By harnessing the power of Python and the diversity of its scientific computing modules, Scikit Learn plays a pivotal role in enhancing data analysis capabilities.
This open-source library, rich in algorithms and utilities, can transform the way we usually perceive data analysis by adding a layer of simplicity, efficiency, and accuracy.
Simplifying the Complexity in Data Analysis
Data analysis often involves a complex web of procedures and computations that could be quite intimidating, especially for beginners.
Scikit Learn simplifies this complexity through its well-documented and user-friendly interfaces.
It removes the barrier to entry, enabling you to focus more on the conceptual understanding of data analysis principles.
Variety of Machine Learning Algorithms
Scikit Learn provides a comprehensive range of supervised and unsupervised learning algorithms, such as linear regression, decision trees, clumping, etc.
Having a wide variety of algorithms opens up possibilities to tackle various complex data analysis demands, from customer segmentation to predictive analytics.
Seamless Data Preprocessing
Data preprocessing is an essential part of data analysis, as it enhances the quality and reliability of your insights.
Scikit Learn provides robust tools for data cleaning, transformation and extraction, making this step more intuitive and less laborious.
Accuracy with Cross-Validation
When applying machine learning algorithms, one concern is how well the model will perform on unseen data.
Scikit Learn offers functionality for cross-validation, an invaluable technique that helps avoid overfitting the model to your data, ultimately enhancing prediction accuracy.
Model Evaluation and Improvement
Model evaluation is vital in determining how effective your analysis has been. Scikit Learn provides a suite of metrics for model evaluation in different contexts.
Furthermore, it also provides functions for model tuning and algorithm parameter optimization, allowing for the honing and refining your model for best results.
Visualization of Data and Results
Another way Scikit Learn enhances your data analysis is by providing tools for model visualization.
Built with integration to Matplotlib in mind, it enables you to create informative visualizations easily. This enhances data interpretation and the communication of results.
Scalability and Performance
Scikit Learn is built around the concept of efficient computing. Despite dealing with large datasets, it ensures scalability and high performance using strategies like support for parallel computing and integration with lower-level languages like C++.
Thriving Community and Ongoing Development
Lastly, as an open-source project, Scikit Learn fosters a growing community of data analysts and developers who continually contribute to its development.
This gives you a platform for learning, sharing, and even contributing to the Scikit Learn project.
Suggested Reading: How to get started with Scikit Learn: A step-by-step tutorial
Regression with Scikit-Learn
In this section, we'll delve into the concept of regression and understand how Scikit-Learn algorithms can apply to real-world problems.
We'll discuss the implementation process and explore the advantages and disadvantages of using regression with Scikit-Learn.
What is Regression?
Regression is a technique in machine learning and statistics that aims to predict continuous-valued output variables based on input features.
It establishes the relationship between the independent variables (features) and the dependent variable (target) by fitting a mathematical model to the data.
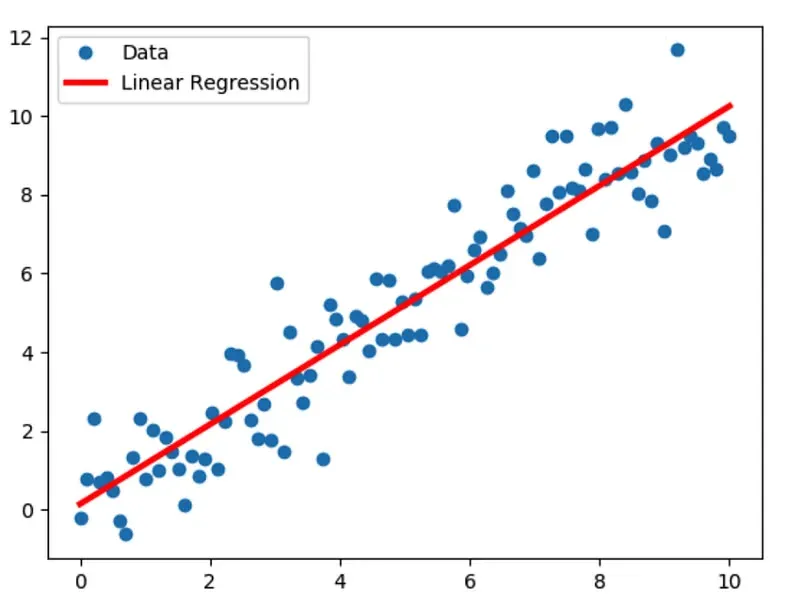
Understanding Regression Algorithms in Scikit-Learn
Scikit-Learn offers a variety of regression algorithms, including:
- Linear Regression
- Ridge Regression
- Lasso Regression
- Elastic Net Regression
- Decision Tree Regression
- Support Vector Regression
These algorithms differ in complexity, regularization techniques, and the way they handle noise in the data, offering flexibility to choose the best model based on your data and requirements.
Real-world Use Cases of Regression
Regression has numerous practical applications, such as:
- Predicting housing prices
- Forecasting sales and demand
- Estimating the lifespan of products
- Analyzing trends and patterns in financial markets
- Modeling the impact of environmental factors on crop yields
Steps to Implement Regression in Scikit: Learn
To implement regression in Scikit Learn, follow these steps:
- Import necessary libraries and the desired regression model
- Load and preprocess the dataset
- Split the dataset into training and testing sets
- Train the regression model on the training data
- Make predictions using the trained model on the test data
- Evaluate the performance of the model using relevant metrics
Advantages and Disadvantages of Regression in Scikit-Learn
Advantages
- Provides an easy-to-understand and interpretable model
- Effective for identifying relationships between variables
- Extensive support for different regression algorithms in Scikit-Learn
Disadvantages
- Sensitive to outliers and noise in the data
- Requires assumption of relationships between features and the target variable
- May underperform with complex non-linear datasets
Clustering in Scikit-Learn
In this section, we will explore the concept of clustering and understand how Scikit-Learn makes it easy to analyze and find patterns in data.
We will cover the implementation of clustering in Scikit Learn and discuss its pros and cons.
What is Clustering?
Clustering is an unsupervised machine-learning technique that aims to group data points with similar characteristics.
Its primary goal is to identify underlying patterns or structures within the dataset.
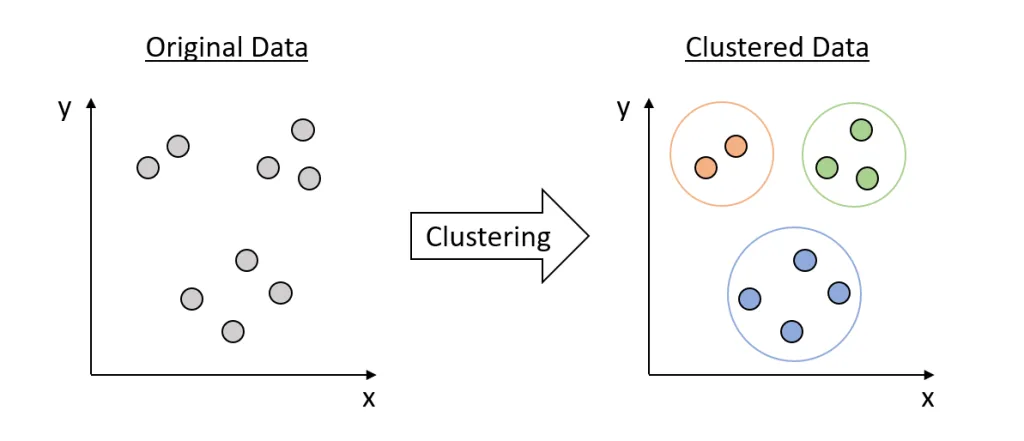
Understanding Clustering Algorithms in Scikit-Learn
Scikit-Learn offers a variety of clustering algorithms, such as:
- K-Means Clustering
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Agglomerative Hierarchical Clustering
- Mean Shift Clustering
- Affinity Propagation
These algorithms differ in defining clusters and handling noisy or outlier data points.
Real-World Use Cases of Clustering
Clustering has numerous practical applications, including:
- Customer segmentation for targeted marketing
- Image segmentation and recognition
- Document grouping and text analysis
- Anomaly detection in network traffic
- Analyzing gene expression data for biological research
Steps to Conduct Clustering in Scikit Learn
To conduct clustering in Scikit Learn, follow these steps:
- Import necessary libraries and the desired clustering algorithm
- Load and preprocess the dataset
- Determine the optimal number of clusters (if applicable)
- Train the clustering algorithm on the data
- Assign data points to their respective clusters
- Analyze and visualize the cluster assignments to gain insights
Pros and Cons of Clustering in Scikit-Learn
Pros
- Unsupervised learning, no need for labeled data
- Helps uncover hidden patterns or categories within data
- A variety of clustering algorithms available in Scikit-Learn
Cons
- Can be sensitive to the initialization and scale of input features
- The optimal number of clusters can be difficult to determine
- Noisy data and outliers can negatively impact cluster formation
Dimensionality Reduction using Scikit-Learn
In this section, we will explore dimensionality reduction—a technique that aids in managing complex, high-dimensional data—and how Scikit-Learn makes implementing this technique simple.
We will discuss real-world applications and both the benefits and limitations of using dimensionality reduction in Scikit-Learn.
What is Dimensionality Reduction?
Dimensionality reduction is a technique used to reduce the number of features in a dataset while preserving its essential structure and patterns.
This process helps optimize computational efficiency and mitigates the "curse of dimensionality" that afflicts machine learning models.
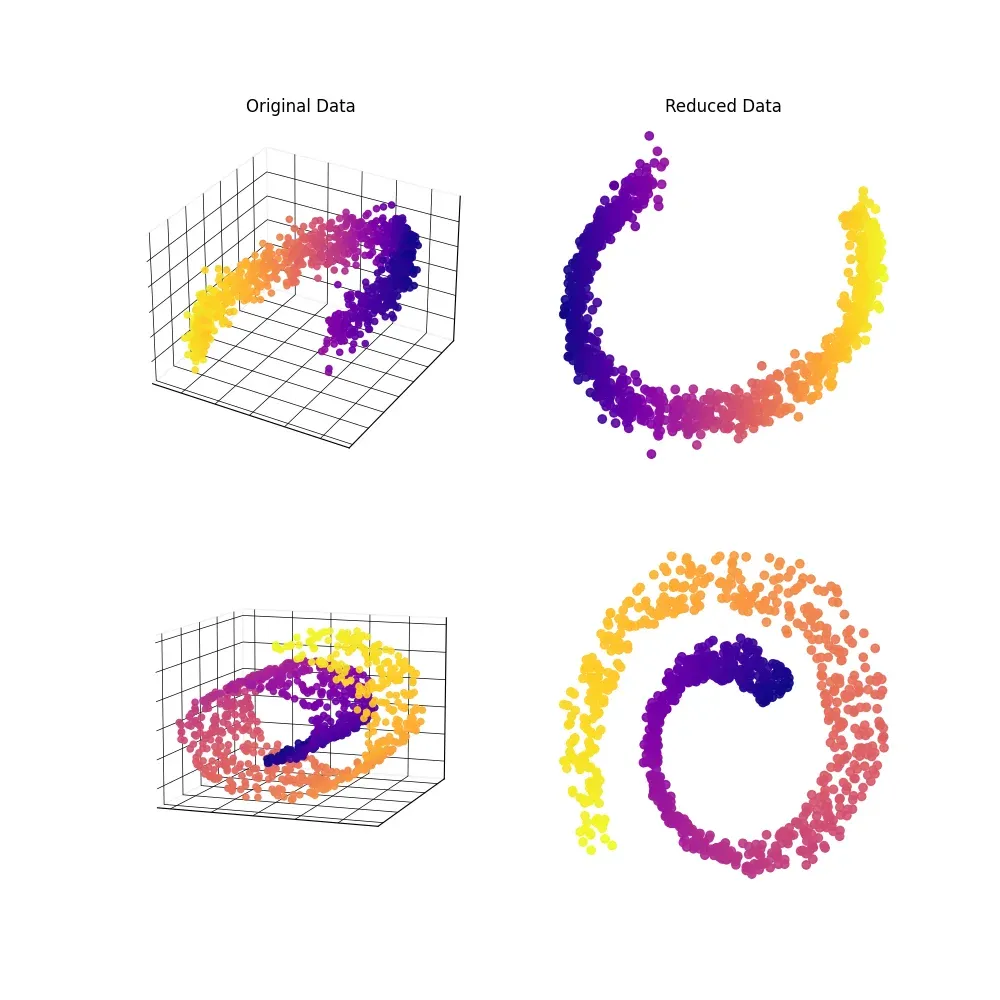
Understanding Dimensionality Reduction Methods in Scikit-Learn
Scikit-Learn provides various dimensionality reduction techniques, such as:
- Principal Component Analysis (PCA)
- Linear Discriminant Analysis (LDA)
- t-Distributed Stochastic Neighbor Embedding (t-SNE)
- Independent Component Analysis (ICA)
These techniques differ in their mathematical foundation and the way they transform high-dimensional data into lower-dimensional representations.
Real-World Applications of Dimensionality Reduction
Dimensionality reduction techniques have numerous applications, including:
- Improving model performance (reducing overfitting)
- Reducing training time for machine learning models
- Data compression (reducing storage consumption)
- Visualization of high-dimensional data (e.g., 2D or 3D plots)
- Noise reduction and outlier detection
Implementation of Dimensionality Reduction in Scikit Learn
To implement dimensionality reduction in Scikit Learn, follow these steps:
- Import necessary libraries and the desired dimensionality reduction technique
- Load and preprocess the dataset
- Determine the optimal number of components (dimensions) to retain
- Fit the dimensionality reduction technique to the data
- Transform the data to a lower-dimensional representation
- Train machine learning models or visualize the transformed data
Benefits and Limitations of Dimensionality Reduction in Scikit-Learn
Benefits
- Removes redundant or irrelevant features, improving model performance
- Reduces model training time and computational resources
- Simplifies data visualization and interpretation
Limitations
- May lose some information during the process
- The optimal number of dimensions to retain can be subjective or unclear
- Results can be sensitive to the choice of parameters or algorithm
Model Selection using Scikit-Learn
In this section, we delve into model selection practices using Scikit-Learn.
We will explore the concept of model selection, its techniques, including real-world deployment, and a step-by-step walkthrough of executing this technique in Scikit-Learn, along with its advantages and challenges.
What is Model Selection?
Model selection is identifying, comparing, and choosing the most suitable machine learning model to solve a specific problem.
It involves estimating the performance of different models and selecting the best performance.
Understanding Model Selection Techniques in Scikit-Learn
Scikit-Learn offers various model selection techniques that make it easy to compare, validate, and choose models. These include:
- Cross-validation techniques like k-fold, stratified k-fold, and leave-one-out.
- Grid search, which systematically traverses through combinations of parameters.
- Randomized search that samples a given number of candidates from a parameter space with a specified distribution.
Real-world deployment of Model Selection
Model selection is widely used in the real world such as:
- Predicting customer churn in telecommunications.
- Medical diagnosis using health records.
- Stock price prediction in finance.
- Identifying spam in emails.
Steps to Perform Model Selection in Scikit Learn
To perform model selection in Scikit Learn, follow these steps:
- Import necessary libraries and models
- Split your data into training and validation sets
- Implement cross-validation with the selected model
- Use GridSearchCV or RandomizedSearchCV for hyperparameter tuning
- Fit the model and make predictions
Pros and Cons of Model Selection in Scikit-Learn
Pros
- Enhances the model’s predictive capabilities.
- Handles overfitting and underfitting effectively.
- Scikit-Learn provides several efficient tools for model selection.
Cons
- It can be computationally expensive, particularly with large datasets and complex models.
- The results may vary based on the chosen validation strategy or the data split.
Preprocessing with Scikit-Learn
In this section, we focus on preprocessing techniques using Scikit-Learn.
We will explore its meaning, techniques, real-world applications, and a practical guide to implementing this technique in Scikit-Learn, along with its benefits and limitations.
What is Preprocessing?
Preprocessing is all the transformations applied to data before feeding it to the machine learning algorithm.
It includes cleaning, normalization, scaling, feature extraction, and encoding.

Understanding Preprocessing Techniques in Scikit-Learn
Scikit-Learn comes with a robust preprocessing module that includes:
- Scaling utilities (StandardScaler, MinMaxScaler)
- Normalization techniques
- Encoding methods (OneHotEncoder, LabelEncoder)
- Feature extraction methods
Real-World Scenarios of Preprocessing
Preprocessing techniques commonly find use in:
- Scaling pixel intensities for image processing.
- Encoding categorical data for housing price predictions.
- Cleaning and filling in missing data for customer segmentation.
Steps to Implement Preprocessing in Scikit-Learn
To conduct preprocessing, follow these steps:
- Install and import necessary libraries and modules
- Load your dataset
- Implement the necessary preprocessing techniques
- Transform the data and fit it to the model
Benefits and Limitations of Preprocessing in Scikit-Learn
Benefits
- Preprocessing removes noise and inconsistencies in the data.
- It makes data suitable for machine learning algorithms, leading to better performance.
Limitations
- Preprocessing can sometimes lead to loss of original data.
- The choice of preprocessing technique can significantly impact the machine learning model’s performance.
Conclusion
Scikit-Learn is an invaluable tool for data analysis due to its comprehensive set of functionalities ranging from preprocessing, model selection, regression, dimensionality reduction, clustering, and more.
The future for Scikit-Learn likely involves further enhancement of existing techniques and integration of cutting-edge machine learning paradigms as the ecosystem continues to evolve.
Scikit-Learn is an accessible yet powerful tool that can enhance your data analysis journey and broaden your understanding of machine learning. Delve into the resources, explore more, and enjoy the process.
Frequently Asked Questions (FAQs)
How does Scikit-learn enhance data analysis?
Scikit-learn brings sophisticated tools for preprocessing, reducing dimensionality, classification, regression, clustering, and more.
It simplifies complex tasks into handy functions, enhancing data analysis by streamlining procedures and saving time.
Can I use Scikit-learn for preprocessing data?
Absolutely! Scikit-learn offers powerful modules for preprocessing.
These include capabilities for data cleaning, inputation, normalization, and feature selection.
It helps you prepare your data for machine learning models.
How does Scikit-learn deal with dimensionality reduction?
Scikit-learn provides numerous techniques to manage high-dimensional data, such as Principal Component Analysis (PCA), t-distributed Stochastic Neighbor Embedding (t-SNE), and Linear Discriminant Analysis (LDA).
These techniques help to reduce noise, improve efficiency, and visualize data.
Can Scikit-learn help with making predictions about my data?
Definitely! Scikit-learn offers machine learning capabilities, i.e., supervised models for making predictions based on known outcomes (regression, classification) and unsupervised models to discover hidden patterns or structures (clustering).
What are the advantages of using Scikit-learn for model evaluation?
Scikit-learn provides built-in functionalities for model evaluation like confusion matrix, precision, recall, F1, and more.
These tools help you assess your models' accuracy, identify issues, fine-tune parameters, and ensure optimal performance.
