Ever wondered how complex Machine Learning works and wished there was a simpler way to understand it?
Well, Scikit Learn may just be the answer you're looking for.
Developed in Python, Scikit Learn isn't some cryptic software but an open-source library meant for everyone intrigued by Machine Learning.
This library steps in to assist us with handling our data, developing models, and even evaluating their success.
No, it doesn't demand you to be an expert in the field.
Whether you're just starting to dip your toes into Machine Learning or you've been journeying in this realm for some time, Scikit Learn has something beneficial for everyone.
Hang around as we get to know Scikit Learn better in this blog. Together, we'll decode its capabilities and understand its contribution to simplifying the maze we know as Machine Learning. Let's make this complicated world an easy one to navigate!
What’s Scikit Learn?
Scikit Learn, oftentimes shortened as "sklearn," is an open-source library in Python that provides simple and efficient tools for data mining and analysis.
Anchored in Python’s scientific computing packages, NumPy and SciPy, it has gained popularity due to its ease of use and broad range of algorithms for machine learning and statistics.
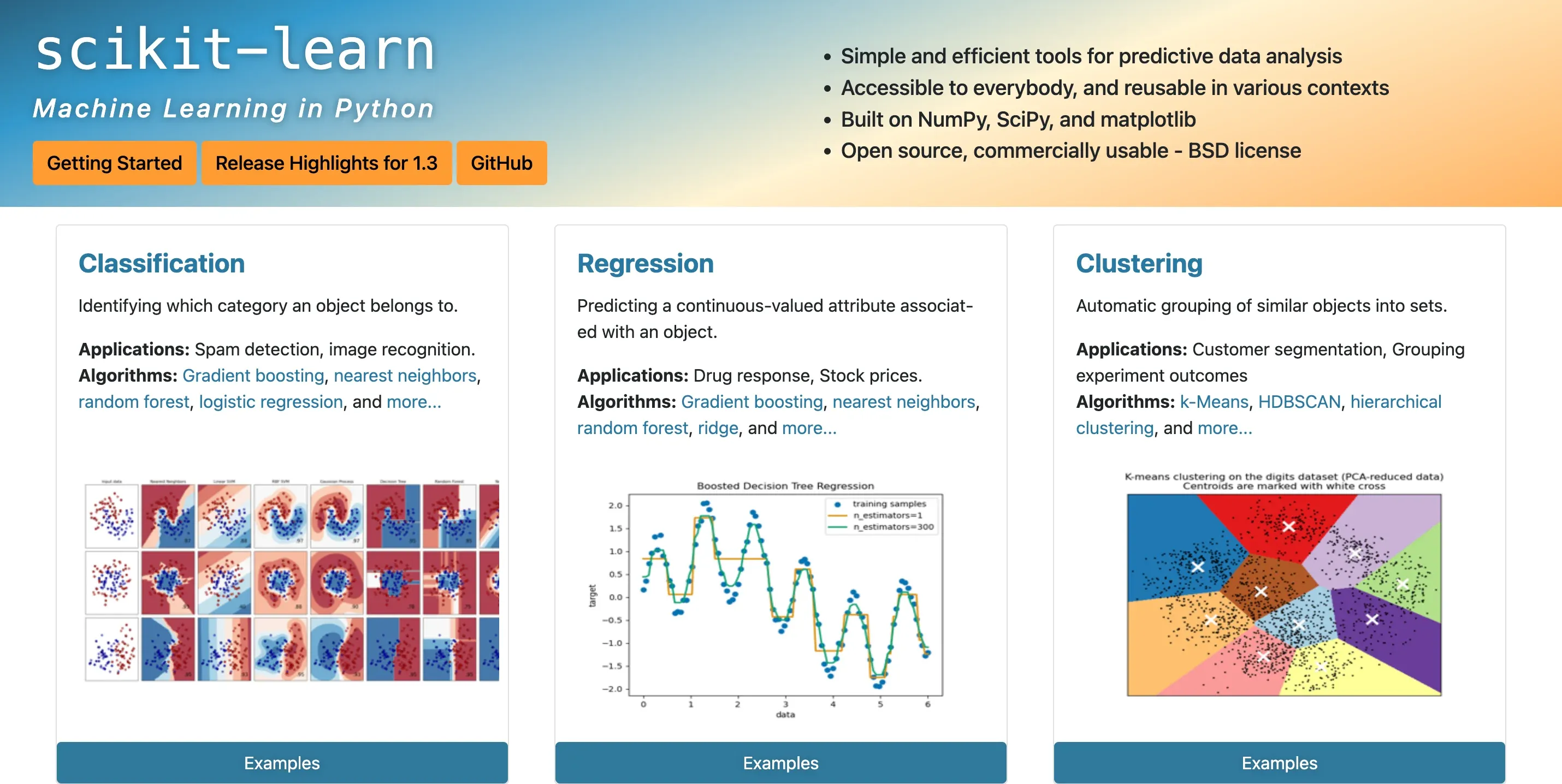
Features of Scikit Learn
Scikit Learn comes packed with a multitude of features that can aid in data analysis.
It includes several classification, regression, and clustering algorithms such as support vector machines, random forests, gradient boosting, k-means, among others.
Furthermore, Sklearn also incorporates tools for model fitting, data preprocessing, model selection, and evaluation.
Applications of Scikit Learn
Scikit Learn finds vast application across multiple industry verticals. From automating tasks with robotic process automation to creating recommendations in applications or websites, Scikit Learn brings several possibilities in image and text data application, customer segmentation, and even in the field of genetic research.
Installing Scikit Learn
Installing Scikit Learn is as straightforward as running a single command in your Python environment - pip install -U scikit-learn.
However, to avoid conflicts with your system packages, it’s usually best to use it within a virtual environment.
The Scikit Learn Community
The Scikit Learn project maintains a strong online community. These interactive groups actively collaborate to improve the library and exchange their experiences, insights, and tips for using Scikit Learn.
The community brings together professional data scientists, industry experts, researchers, and enthusiasts, fostering learning and growth.
Supervised Learning in Scikit Learn
Supervised learning is a type of machine learning where we 'supervise’ the model by providing it with labeled input and output data during training.
The model then learns patterns from this data, which is then used to predict outcomes for unseen data.
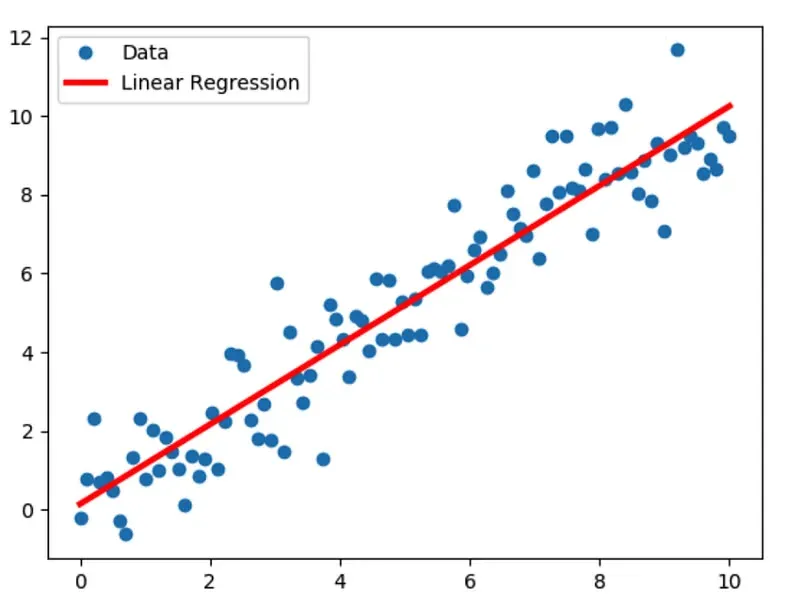
Regression
Regression is a supervised learning process where the output is a continuous value, like a price or weight.
Scikit learn has various regression algorithms you can utilize such as Linear Regression, Ridge Regression, and Lasso Regression.
Classification
Classification, another supervised learning method, assumes the output to be discrete categories like spam/not-spam or fraud/not-fraud.
Tools like K-Neighbors, Support Vector Machines, and Random Forests are some of Scikit Learn's efficacious classification algorithms.
Model Selection and Evaluation
Sklearn provides solutions to ensure robust model performance through tools for cross-validation, hyperparameter tuning, learning curves, and performance metrics.
Working with Text Data
Scikit Learn is ideal for text data, offering tools for feature extraction, tokenization, and feature engineering.
Unsupervised Learning in Scikit Learn
Unsupervised learning uncovers hidden patterns in data where we don’t have a target outcome to predict.
By applying methods like clustering, we find structures within the data.
Clustering Algorithms
Clustering is the grouping of similar instances.
Scikit Learn offers many clustering algorithms like K-Means, DBSCAN, and Hierarchical Clustering.
Dimensionality Reduction
Scikit Learn's dimensionality reduction capabilities provide tools like PCA and T-SNE to help us reduce the number of variables in our analysis.
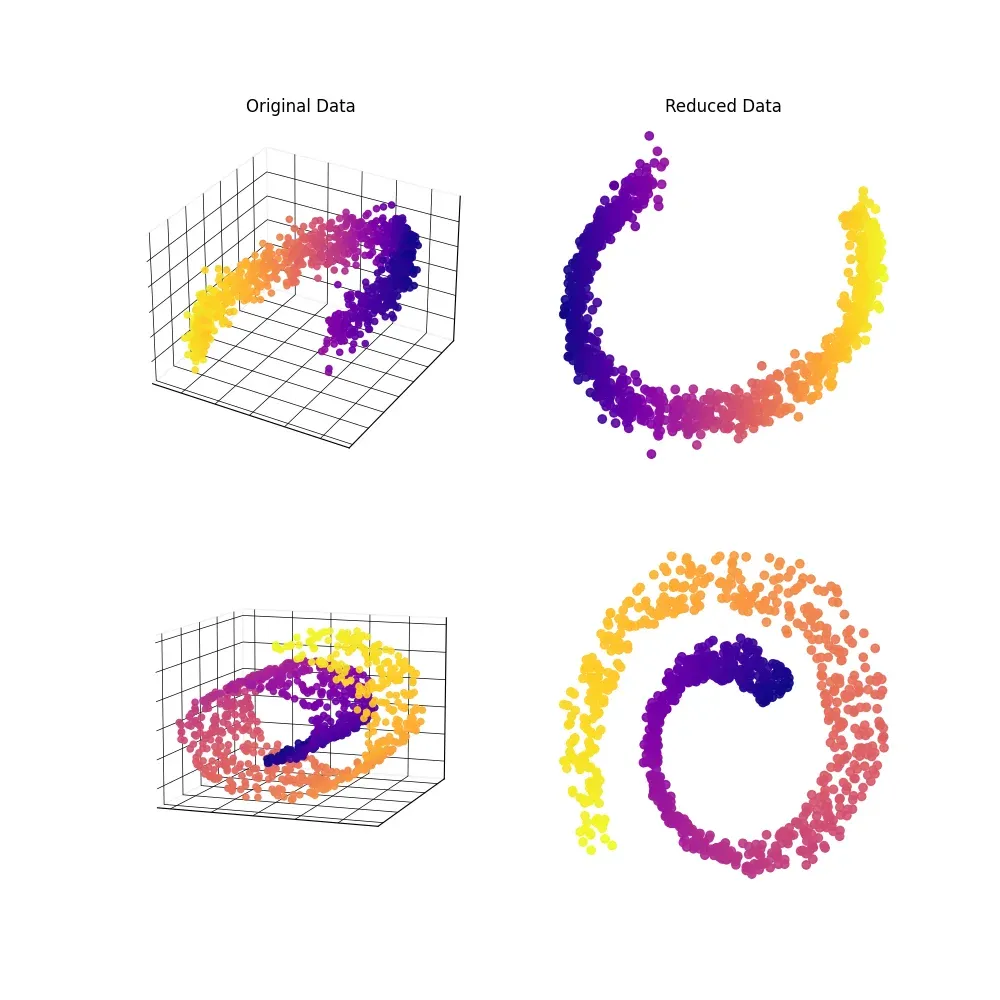
Manifold Learning
Sklearn provides Manifold Learning algorithms that reduce dimensionality whilst trying to preserve certain properties of the original data, like t-SNE or MDS.
Outlier Detection
Outlier detection is a crucial part of unsupervised learning.
Sklearn can identify the odd one out using methods like Z-score, DBSCAN, or an Isolation Forest.
Preprocessing Techniques with Scikit Learn
The primary goal of preprocessing is to enhance the quality of your data so that machine learning models can make better predictions.
In the following subsections, we will explore data normalization, encoding categorical variables, feature extraction, missing data handling, and feature selection.
Data Normalization and Scaling
Data normalization and scaling are essential steps in preprocessing, as they bring features to the same scale, which often leads to improved model performance.
Scikit Learn provides several methods for normalization and scaling, such as MinMaxScaler, StandardScaler, and RobustScaler.
Encoding Categorical Variables
Categorical variables often hold vital information, but machine learning algorithms require numerical data.
Scikit Learn provides various techniques for encoding categorical variables, such as Label Encoding and One-Hot Encoding.
These methods convert categorical data into numerical format, allowing models to capture patterns within the data more effectively.
Feature Extraction
Feature extraction plays a critical role in reducing dimensionality, extracting relevant information, and improving model performance.
Scikit Learn offers numerous techniques for feature extraction, covering both text and image data. Some examples include CountVectorizer, TfidfVectorizer, and PCA.
Dealing with Missing Data
Real-world datasets often contain missing values, which can negatively impact model performance. Handling missing data is an important preprocessing step, and Scikit Learn provides several techniques to manage such cases.
SimpleImputer can be used to replace missing values with either mean, median, or mode, depending on the situation.
Suggested Reading:Scikit Learn: The advanced algorithm of Machine Learning
Feature Selection
Sometimes datasets may contain irrelevant or redundant features that could decrease model performance. Feature selection helps identify the most informative features.
Scikit Learn has a variety of feature selection techniques available, including VarianceThreshold, SelectKBest, and recursive feature elimination.
Model Selection and Evaluation
Evaluating machine learning models is vital to assess a model's performance accurately and identify the most suitable model for your specific problem.
We will discuss cross-validation, hyperparameter tuning techniques, evaluation metrics, working with imbalanced datasets, and model persistence and deployment.
Cross-Validation
Cross-validation is a robust technique for assessing model performance by partitioning the dataset into train and test subsets multiple times.
Scikit Learn provides easy-to-use functions for cross-validation like cross_val_score and cross_validate.
Hyperparameter Tuning using GridSearchCV and RandomizedSearchCV
Tuning hyperparameters can significantly improve model performance. Scikit Learn includes GridSearchCV and RandomizedSearchCV methods, enabling an exhaustive search over specified hyperparameter values, saving time and effort.
Evaluation Metrics for Classification, Regression, and Clustering
Metrics aid in understanding model performance and selecting the best model. Scikit Learn offers various evaluation metrics for classification (e.g., accuracy, precision, recall), regression (e.g., mean squared error, R-squared), and clustering (e.g., adjusted Rand index, silhouette score).
Working with Imbalanced Data Sets
Imbalanced data poses challenges when training models. Scikit Learn provides techniques for handling imbalanced data, such as under-sampling, over-sampling, and the combination of both using imbalanced-learn library.
Model Persistence and Deployment
Deploying a trained model is an important aspect of the machine learning workflow. Scikit Learn has built-in functions for model persistence and deployment, such as pickle and joblib, making it possible to store and reload trained models easily.
Ensemble Methods
Ensemble methods combine multiple base models to enhance the overall performance.
In this section, we will discuss various ensemble techniques in Scikit Learn, including bagging and boosting methods, Random Forest, Gradient Boosting, AdaBoost, and XGBoost.
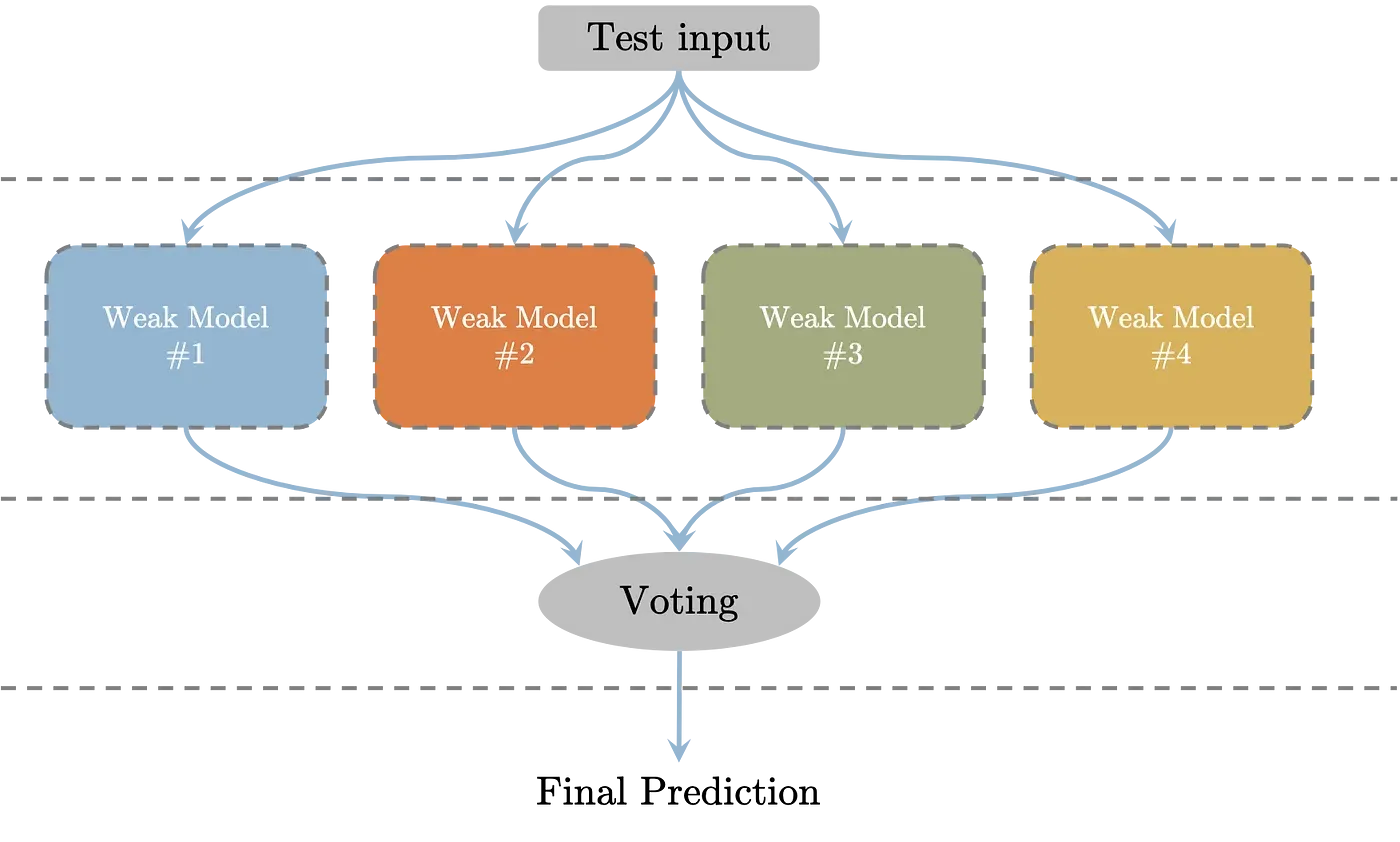
Bagging and Boosting Techniques
Bagging and boosting are popular ensemble methods available in Scikit Learn. Bagging techniques, such as BaggingClassifier or BaggingRegressor, reduce variance by averaging multiple models' predictions.
Boosting techniques, like AdaBoostClassifier or GradientBoostingRegressor, enhance accuracy by combining the predictions of multiple weak models.
Random Forest
Random Forest is an ensemble method that generates decision trees and aggregates their predictions.
Scikit Learn provides RandomForestClassifier and RandomForestRegressor implementations, which can be used for classification and regression problems, respectively.
Gradient Boosting
Gradient Boosting is a popular boosting algorithm that minimizes residual error using gradient descent.
Scikit Learn offers GradientBoostingClassifier and GradientBoostingRegressor for classification and regression tasks, respectively.
AdaBoost
AdaBoost (Adaptive Boosting) is another popular boosting method that adapts and updates the individual learners' weights during the training process.
Scikit Learn provides AdaBoostClassifier and AdaBoostRegressor for classification and regression challenges, respectively.
XGBoost
XGBoost (Extreme Gradient Boosting) is a highly optimized and efficient gradient boosting algorithm.
Although not built into Scikit Learn, you can easily use XGBoost with Scikit Learn's API.
This algorithm is known for its scalability and effectiveness, making it a popular choice for data scientists and machine learning engineers.
Advanced Techniques in Scikit Learn
In this section, we'll explore advanced techniques in Scikit Learn that make this library a powerful tool for data analysis, model pipelines, custom transformers and estimators, feature unions, multi-output regression and classification, and multi-task learning.
Model Pipelines
Model pipelines are a convenient way to streamline your workflow, as they allow you to chain together multiple steps in an organized and efficient manner.
Scikit Learn's Pipeline class makes it easy to implement these pipelines, enabling seamless data preprocessing, model training, and cross-validation.
Custom Transformers and Estimators
Scikit Learn allows you to create custom transformers and estimators to fit your specific needs.
By implementing fit(), transform(), and predict() methods, you can extend Scikit Learn's functionality and tailor it to your unique data and models.
Feature Unions
Feature Union in Scikit Learn is a helpful technique for combining multiple feature extraction mechanisms and preprocessing steps into a single transformer.
This enables you to concatenate features obtained from different sources or transformations into a single, structured dataset.
Multi-output Regression and Classification
Scikit Learn supports multi-output regression and classification tasks, allowing you to handle cases where multiple target variables need to be predicted at once.
By leveraging multi-output estimators, you can predict multiple outcomes simultaneously and handle tasks that require predicting multiple variables.
Multi-task Learning
Multi-task learning in Scikit Learn involves training a single model to solve multiple problems, ultimately improving the overall performance and generalization capabilities of the model.
Joint feature learning can be used to handle several related tasks, enabling knowledge transfer between tasks and boosting efficiency.
Deep Learning with Scikit Learn
In this section, we'll dive into the world of deep learning with Scikit Learn, exploring neural networks, multi-layer perceptrons (MLPs), convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transfer learning.
Neural Networks in Scikit Learn
Scikit Learn provides support for neural networks through its MLPClassifier and MLPRegressor classes.
These classes offer an easy-to-use interface for training multi-layer perceptron models for classification and regression tasks.
Multi-layer Perceptrons (MLPs)
MLPs are a type of feedforward artificial neural network that consists of multiple layers of interconnected nodes.
In Scikit Learn, you can create MLPs by configuring the architecture, activation functions, and learning algorithms to suit your problem.
Convolutional Neural Networks (CNNs)
Although Scikit Learn does not directly support CNNs, it's possible to build and train convolutional layers using Keras or TensorFlow.
CNNs are particularly useful for image recognition and processing tasks, thanks to their ability to capture spatial patterns in data.
Suggested Reading:Scikit Learn: The advanced algorithm of Machine Learning
Recurrent Neural Networks (RNNs)
Scikit Learn also lacks native support for RNNs, but you can implement them with third-party libraries such as Keras or TensorFlow.
RNNs excel at tasks that require sequence analysis, like natural language processing and time series predictions.
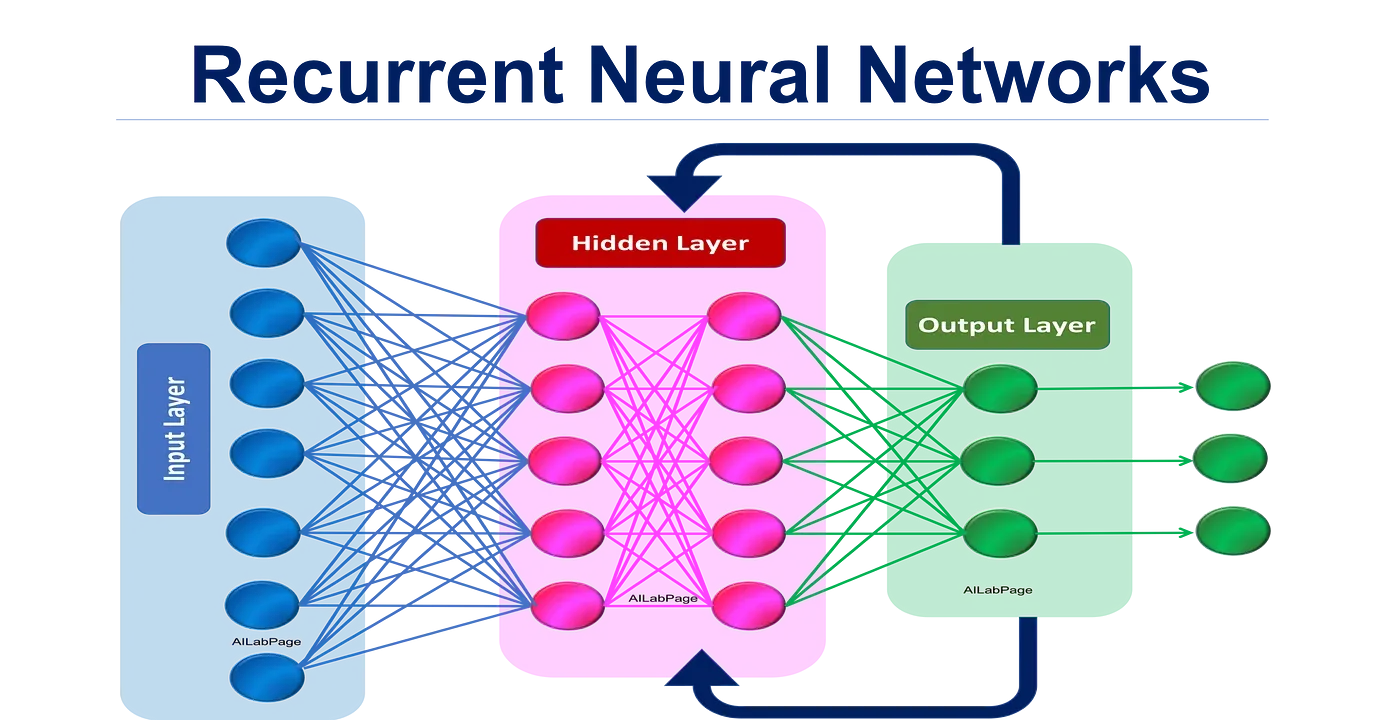
Transfer Learning
Transfer learning involves using a pre-trained model to tackle new, related tasks. With Scikit Learn, you can utilize transfer learning by fine-tuning pre-trained models (e.g., from Keras or TensorFlow) to adapt to the specific needs of your problem.
Tips to Improve Model Performance
Let's discuss key tips for improving model performance when using Scikit Learn, as we cover feature engineering, regularization techniques, handling overfitting and underfitting, model simplification, and early stopping.
Feature Engineering
Feature engineering involves creating new features or modifying existing ones to improve model performance.
In Scikit Learn, you can use its preprocessing and feature selection tools to enhance and refine your features, ultimately boosting model accuracy.
Regularization Techniques
Regularization techniques prevent overfitting by adding a penalty term to the loss function.
Scikit Learn offers various regularization methods, such as L1 and L2 regularization, which can help control your model's complexity and improve generalization.
Handling Overfitting and Underfitting
Overfitting occurs when a model performs well on training data but poorly on new data. Underfitting happens when a model cannot accurately capture the underlying trends in the data.
To address these issues in Scikit Learn, use techniques like cross-validation, train/test splits, and regularization to find the right balance between complexity and generalizability.
Model Simplification
Sometimes, simpler models yield better performance. By reducing your model's complexity, you can improve its learning capabilities and make it less prone to overfitting.
In Scikit Learn, experiment with simpler algorithms and parameter configurations to find the right balance of simplicity and predictive power.
Early Stopping
Early stopping halts the training process when model performance stops improving or starts deteriorating. This technique can prevent overfitting and save computational resources by stopping training at the optimal point.
Scikit Learn's MLPClassifier and MLPRegressor classes support early stopping through customizable parameters.
Conclusion
Scikit Learn provides robust and comprehensive tools to assist throughout the lifecycle of machine learning projects.
From preprocessing techniques such as normalization, encoding, dealing with missing data, to model selection and hyperparameter tuning,
Scikit Learn proves to be a reliable library. Its wide range of metrics for model evaluation ensures you can accurately analyze your model's performance.
Handling imbalanced data sets and deploying models are also made simpler with Scikit Learn's diversified functionalities.
Further, the wide selection of ensemble methods gives you the flexibility to experiment and optimize your predictive models to achieve even better results.
Whether you are working on classification, regression, or even clustering problems, Scikit Learn caters to your needs with ensemble methods that include Bagging, Boosting, Random Forest, AdaBoost, and even support for XGBoost.
Mastering Scikit Learn equips you with a powerful toolbox for data analysis and machine learning, amplifying your capacity to generate valuable insights and data-driven solutions.
Frequently Asked Questions (FAQs)
How does Scikit-learn enhance data analysis?
Scikit-learn brings sophisticated tools for preprocessing, reducing dimensionality, classification, regression, clustering, and more.
It simplifies complex tasks into handy functions, enhancing data analysis by streamlining procedures and saving time.
How to use Scikit-learn for preprocessing data?
Absolutely! Scikit-learn offers powerful modules for preprocessing. These include capabilities for data cleaning, inputation, normalization, and feature selection.
It helps you prepare your data for machine learning models.
How does Scikit-learn deal with dimensionality reduction?
Scikit-learn provides numerous techniques to manage high-dimensional data, such as Principal Component Analysis (PCA), t-distributed Stochastic Neighbor Embedding (t-SNE), and Linear Discriminant Analysis (LDA). These techniques help to reduce noise, improve efficiency, and visualize data.
Can Scikit-learn help with making predictions about my data?
Definitely! Scikit-learn offers machine learning capabilities, i.e., supervised models for making predictions based on known outcomes (regression, classification) and unsupervised models to discover hidden patterns or structures (clustering).
What are the advantages of using Scikit-learn for model evaluation?
Scikit-learn provides built-in functionalities for model evaluation like confusion matrix, precision, recall, F1, and more.
These tools help you assess your models' accuracy, identify issues, fine-tune parameters, and ensure optimal performance.
