Did you know that according to KDnuggets, almost 68% of people working with data and machine learning use Scikit Learn - a Python library created to make these tasks easier?
It's quite impressive when you think about it, but even with so many people using it, there's still a roadblock.
The learning curve for Scikit Learn can seem pretty steep when you're starting from scratch.
Maybe you've heard colleagues talking about Scikit Learn and how it has helped them tackle challenges related to data analysis and prediction.
You're interested in finding out more, but before even getting started, complex terminology starts to pile up, leaving you a bit overwhelmed.
And that's why we're here: to break down Scikit Learn into digestible, straightforward steps that'll lead you through the basics, clear up any confusion in the process, and help you understand how to harness its power to work with data and build predictions.
Let's dive into the world of Scikit Learn, one step at a time.
Simply put, Scikit Learn is a free software machine learning library for Python programming language. It extends Python's functionality to include robust options for modeling and problem solving, making data-driven predictions and insights more accessible.
Why is Scikit Learn useful?
Scikit Learn brings an array of benefits to the table. It integrates well with other Python libraries, provides a diverse collection of algorithms for various machine learning tasks, and backs it all up with extensive documentation.
This wide array of tools and relative ease of use make it a go-to resource for anyone wanting to install Scikit Learn and dive into data analysis on the platform.
Key features of Scikit Learn
Among its myriad of features, Scikit Learn offers comprehensive tools for preprocessing data, assessing the performance of algorithms, and fine-tuning model parameters.
Its versatility allows it to handle large datasets and run complex algorithms with high efficiency.
Real-world applications of Scikit Learn
Scikit Learn has found its place across industries, powering the recommendation systems of ecommerce platforms, helping with credit risk analysis in finance, aiding early disease detection in healthcare, and even predicting election outcomes in political science.
Suggested Reading:
How to get started with Scikit Learn: A step-by-step tutorial
Installing Scikit Learn
To install Scikit Learn, you simply need to run the command !pip install -U scikit-learn in your Python environment.
Understanding the Basics of Scikit Learn
Beyond installation, there are some foundational concepts that are vital to gaining mastery of Scikit Learn.
Scikit Learn's API design
Scikit Learn’s API design is centered around fundamental building blocks known as estimators.
Each estimator can be initialized, have models fitted to data, and use these models to make predictions.
Main components: estimators, transformers, and predictors
Scikit Learn has three core components you should get acquainted with: Estimators, used for modeling; Transformers, applied to preprocess data; and Predictors, which tie everything together, making predictions based on the fitted model.
Dataset formats supported by Scikit Learn
While Scikit Learn can support multiple dataset formats, it most commonly works with Numpy arrays.
Here each instance (sample) represents a row, and each column corresponds to a feature.
Loading datasets for Scikit Learn
Scikit Learn provides easy access to a handful of public datasets like Iris and Digits, to your benefit.
You can load these datasets by calling functions like load_digits().
Splitting the dataset into training and testing sets
Remember, you'll need to split your dataset into two subsets: a training set and a test set.
Scikit Learn’s train_test_split function makes this task a breeze.
Data Preprocessing with Scikit Learn
Before you dive headfirst into modeling your data, you must first ensure it's properly sanitized and prepared.
Standardizing and normalizing data
Data standardization and normalization ensure that all data abides by a common scale, without any distortions.
Scikit Learn’s preprocessing library provides a scale function that standardizes your data.
Encoding categorical variables
Machine learning algorithms prefer numerical data. If your dataset includes categorical variables, you need to convert them into numerical ones – a process called encoding.
Scikit Learn's LabelEncoder function makes this process simple.
Handling missing data
Real-world datasets often contain missing data.
Scikit Learn's SimpleImputer provides an excellent solution for this issue, allowing you to fill the missing spots with statistical strategies.
Feature extraction
Scikit Learn has tools to convert each input item (like text or an image) into a set of numerical features.
For instance, the CountVectorizer function makes text classification tasks easier by converting words into numerical vectors.
Feature selection
Scikit Learn employs several techniques for feature selection, like Recursive Feature Elimination (RFE), helping you focus on the features that matter most.
Supervised Learning: Classification
The field of supervised learning is vast and diverse, but don't worry!
Our focus here is on classification, a part of supervised learning where we use patterns to predict discrete output values.
Thanks to Scikit Learn, we can simplify a lot of the complexity involved.
Let's dive deeper into its major techniques.
Logistic Regression
We kickstart our classification journey with logistic regression, a fundamental algorithm that predicts the probability of categorical dependent variables.
In simple terms, if you want to predict an outcome that can be distinctly classified into one group or another (such as 'Yes' or 'No', 'Good' or 'Bad'), Logistic Regression is your algorithm of choice.
In Scikit Learn, you'll import the Logistic Regression module, fit it to your dataset, and voila, you are now predicting outcomes!
Here's an example:
from sklearn.linear_model import LogisticRegressionlogisticR = LogisticRegression()logisticR.fit(X_train, y_train)predictions = logisticR.predict(X_test)
Support Vector Machines (SVM)
Next up is Support Vector Machines, a powerful tool used for both classification and regression.
But how does SVM work?
Think of it as a hardworking artist who wants nothing more than to find a line (or hyperplane in multiple dimensions) that best separates two classes.
Are there multiple possible lines? Sure. But SVM finds the best one, and by "best", we mean the line that creates the maximum separating margin between the classes.
Scikit Learn again simplifies this for us:
from sklearn import svmsvm_clf = svm.SVC()svm_clf.fit(X_train, y_train)predictions = svm_clf.predict(X_test)
Suggested Reading:
How to get started with Scikit Learn: A step-by-step tutorial
Decision Trees
Decision Trees are like playing a game of 20 questions. They use a tree-like model of decisions to go through your data and make classifications. And just like in our game, the choices made can guide you to different outcomes.
Meanwhile, here's a quick example of how Scikit Learn achieves this:
from sklearn.tree import DecisionTreeClassifiertree_clf = DecisionTreeClassifier()tree_clf.fit(X_train, y_train)predictions = tree_clf.predict(X_test)
K-Nearest Neighbors (KNN)
Last but certainly not least, K-Nearest Neighbors (KNN) is like voting for outcomes. Each new classification is done by 'asking' its neighboring data points, which 'vote' to decide the outcome.
Scikit Learn steps in here too:
from sklearn.neighbors import KNeighborsClassifierknn = KNeighborsClassifier()knn.fit(X_train, y_train)predictions = knn.predict(X_test)
And just like that, you're classifying with Scikit Learn. Whether with K-Nearest Neighbors or Decision Trees, your road to master Scikit Learn is well underway.
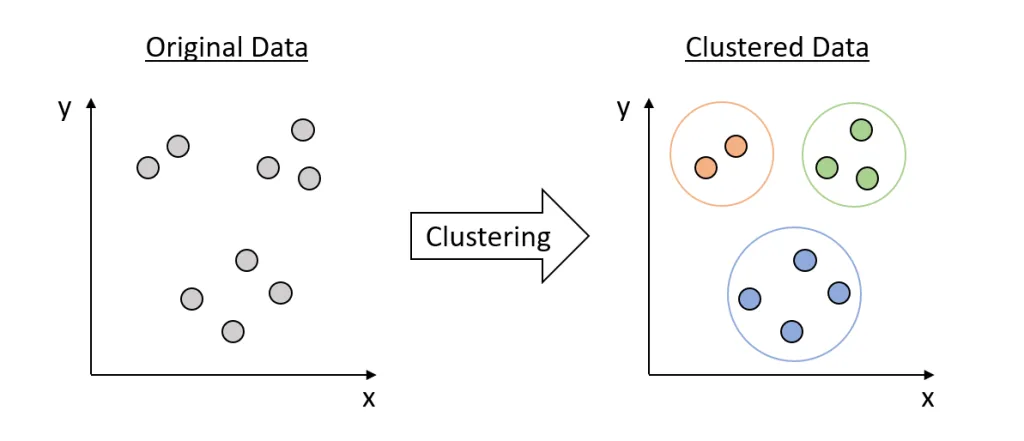
Supervised Learning: Regression
Time to explore another instance of supervised learning - regression. While classification dealt with discrete, categorical outcomes, regression is all about continuous outcomes. If you want to predict things like house prices, weather, or stock performance, regression models are your allies.
So, let's navigate through this realm with the help of our trusted companion, Scikit Learn.
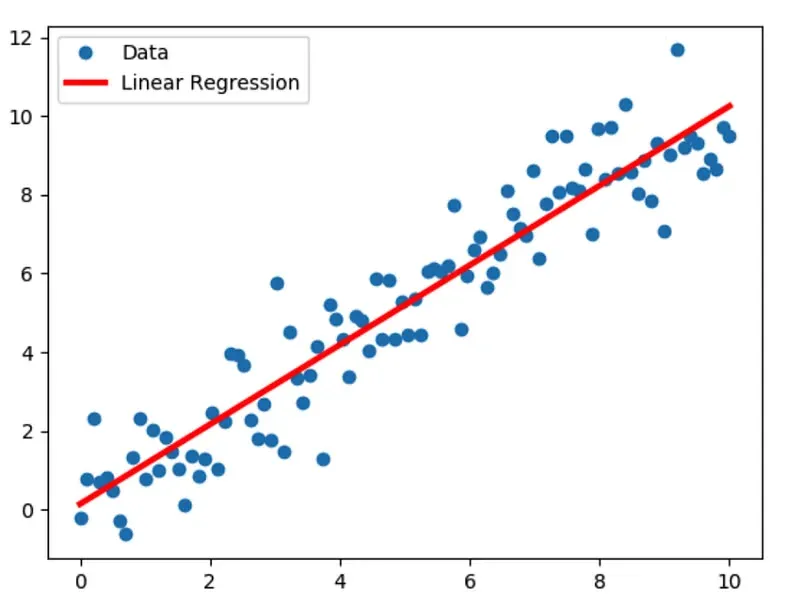
Linear Regression
What better place to start than good old Linear Regression, predicting a dependent variable value based on independent variables. Or, in simpler words, finding a straight line that fits the best amongst a scatter of points.
Scikit Learn bathes us in its warm, simplifying light:
from sklearn.linear_model import LinearRegressionlin_reg = LinearRegression()lin_reg.fit(X_train, y_train)predictions = lin_reg.predict(X_test)
Ridge Regression
But what if our data isn't simple enough for a straight line to fit? Ridge Regression has a solution, introducing a degree of bias into the regression equation.
It restricts coefficients and helps to reduce model complexity and multi-collinearity.
Code with Scikit Learn is elegantly straightforward:
from sklearn.linear_model import Ridgeridge_reg = Ridge()ridge_reg.fit(X_train, y_train)predictions = ridge_reg.predict(X_test)
Lasso Regression
Next, we meet Lasso Regression, another technique to make your model's outcomes better, especially helpful when dealing with datasets with a large number of features. Our friend Scikit Learn efficiently handles this:
from sklearn.linear_model import Lassolasso_reg = Lasso()lasso_reg.fit(X_train, y_train)predictions = lasso_reg.predict(X_test)
ElasticNet Regression
To end our journey through regression, the combines the powers of Ridge and Lasso Regression. If you're dealing with multiple features that are correlated with one another, ElasticNet is a perfect fit.
Implement this:
from sklearn.linear_model import ElasticNeten_reg = ElasticNet()en_reg.fit(X_train, y_train)predictions = en_reg.predict(X_test)
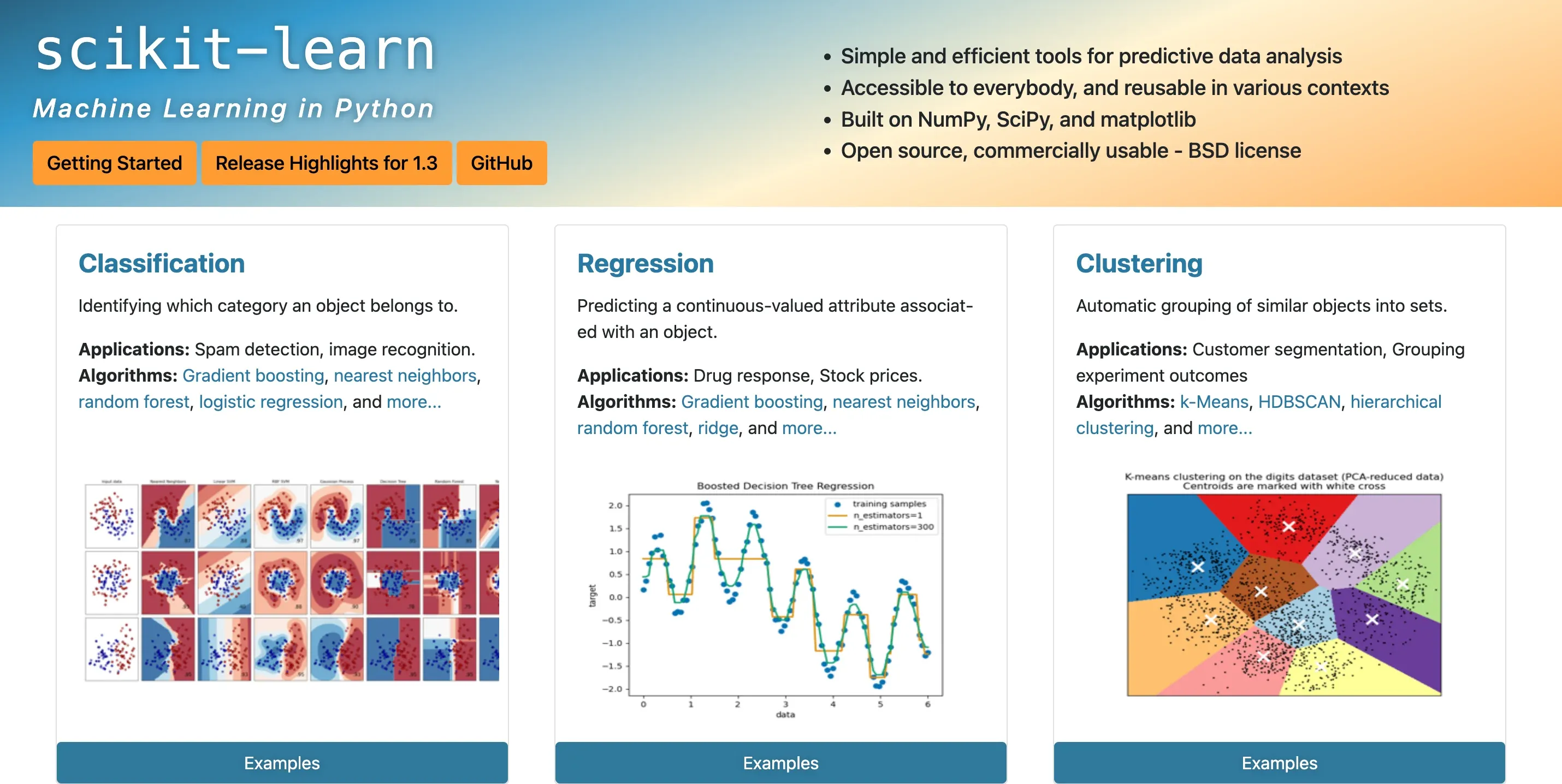
Unsupervised Learning: Dimensionality Reduction
As we step into the realm of unsupervised learning, we'll explore dimensionality reduction techniques. "Why?" you might ask.
Well, more data isn't always the answer, especially when it leads to unwanted noise, overfitting, or sluggish processing.
Talking about Scikit Learn, we'll dive into its arsenal of tools for dimensionality reduction.
Principal Component Analysis (PCA)
First stop, Principal Component Analysis, a statistical method that compresses a dataset's dimensions while preserving as much of the original information as possible.
In other words, PCA seeks to find the principal components that best represent the underlying structure of the data.
Scikit Learn's magic is on display again:
from sklearn.decomposition import PCApca = PCA(n_components=2)reduced_data = pca.fit_transform(X)
T-distributed Stochastic Neighbor Embedding (t-SNE)
Next, we have t-SNE, a fan-favorite for visualizing high-dimensional data. By minimizing the divergence between two probability distributions, t-SNE can accurately map data points from high dimensions to a low-dimensional space.
With Scikit Learn, t-SNE is a breeze:
from sklearn.manifold import TSNEtsne = TSNE(n_components=2, perplexity=30)reduced_data = tsne.fit_transform(X)
Linear Discriminant Analysis (LDA)
While Linear Discriminant Analysis is often associated with classification, its dimensionality reduction prowess is significant too! LDA projects your data into a lower-dimensional space while maximizing class separation.
Bring Scikit Learn to the rescue:
from sklearn.discriminant_analysis import LinearDiscriminantAnalysislda = LinearDiscriminantAnalysis(n_components=2)reduced_data = lda.fit_transform(X, y)
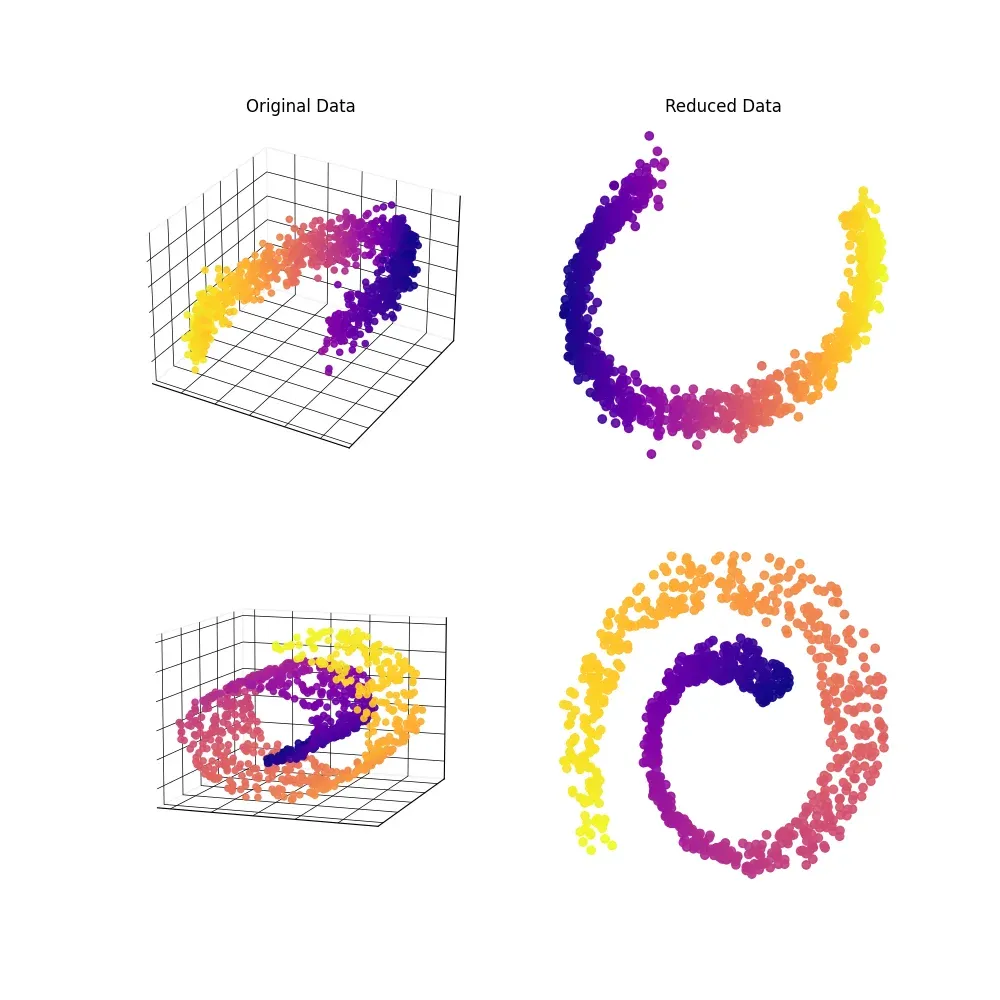
Truncated Singular Value Decomposition (tSVD)
Finally, let's discuss Truncated Singular Value Decomposition. Think of it as PCA's cousin—using tSVD for dimensionality reduction compresses the dataset while retaining as much original information as possible.
Scikit Learn has us covered:
from sklearn.decomposition import TruncatedSVDtsvd = TruncatedSVD(n_components=2)reduced_data = tsvd.fit_transform(X)
Now you've unlocked another Scikit Learn treasure - dimensionality reduction techniques! Go on and experiment, and remember, less is sometimes more.
Model Evaluation and Selection
As you continue your Scikit Learn journey, it's crucial to evaluate and select the right model. Too many questions—Did my model over- or under-fit? Are my hyperparameters ideal?—demand answers before a model can be trusted. So let's dive in.
Cross-validation
Model selection starts with Cross-validation, the process of partitioning a dataset to assess a model's performance. With Scikit Learn, performing cross-validation is delightfully simple:
from sklearn.model_selection import cross_val_scorescores = cross_val_score(model, X, y, cv=5)
Hyperparameter tuning with GridSearchCV and RandomizedSearchCV
Next, fine-tune your hyperparameters with GridSearchCV and RandomizedSearchCV. Better hyperparameters=better models.
Scikit Learn makes this easy:
from sklearn.model_selection import GridSearchCVparameter_grid = {'hyperparameter': [values]}grid_search = GridSearchCV(estimator=model, param_grid=parameter_grid, cv=5)grid_search.fit(X, y)from sklearn.model_selection import RandomizedSearchCVrandomized_search = RandomizedSearchCV(estimator=model, param_distributions=parameter_grid, cv=5)randomized_search.fit(X, y)
Evaluation metrics for classification, regression, and clustering
Model evaluation would be incomplete without its trusty sidekick, evaluation metrics. They assess classification (accuracy, F1 score), regression (MSE, R^2), and clustering (Silhouette score).
Scikit Learn elegantly computes these:
from sklearn.metrics import accuracy_score, mean_squared_error, silhouette_score
Dealing with imbalanced datasets
Life isn't always fair, especially when dealing with imbalanced datasets. Check out Scikit Learn's resampling techniques, like SMOTE and ADASYN, to balance class distributions.
from imblearn.over_sampling import SMOTE, ADASYNsmote_resampler = SMOTE()X_resampled, y_resampled = smote_resampler.fit_resample(X, y)
Model persistence and deployment
Last but not least, preserve your beloved model with Scikit Learn's joblib package and deploy it confidently!
from sklearn.externals import joblib.dump(model, 'model_file.pkl')loaded_model = joblib.load('model_file.pkl')
With this, you've conquered model evaluation and selection! Scikit Learn's vast array of tools will help you fine-tune and validate models.
Conclusion
That’s it, We’ve gone through classification, regression, unsupervised learning techniques and, finally, model evaluation and selection.
Scikit Learn is a powerful ally in data analysis and machine learning, offering a comprehensive library for modern data scientists.
As you continue to learn and experiment with Scikit Learn, be sure to tap into its great resources, like the official documentation and community forums.
Keep practicing, innovating, and growing.
Frequently Asked Questions (FAQs)
What is Scikit-learn and why to use it?
Scikit-learn is an open-source Python library offering user-friendly tools for data analysis and machine learning.
With a vast array of algorithms, it's perfect for newcomers and experts wanting to streamline their modeling process.
How to install Scikit-learn?
To install Scikit-learn, simply run pip install scikit-learn or conda install scikit-learn in your terminal or command prompt. Ensure you have Python and the necessary dependencies installed beforehand.
What are the key steps in a Scikit-learn workflow?
The typical Scikit-learn workflow includes:
- Loading and preparing the data.
- Splitting data into training and test sets.
- Creating a model using an appropriate algorithm.
- Fitting the model to your data.
- Evaluating the model and iterating as required.
How to choose the right algorithm for my dataset?
Scikit-learn provides a handy algorithm cheat sheet to help you decide. Always consider your dataset's size, structure, and desired outcomes for an appropriate choice.
Can Scikit-learn handle big data?
Scikit-learn performs well with small-to-medium-sized datasets.
For big data, use specialized tools like Dask-ML, H2O, or Apache Spark's MLlib, which are designed to manage such demands efficiently.
